Ideation
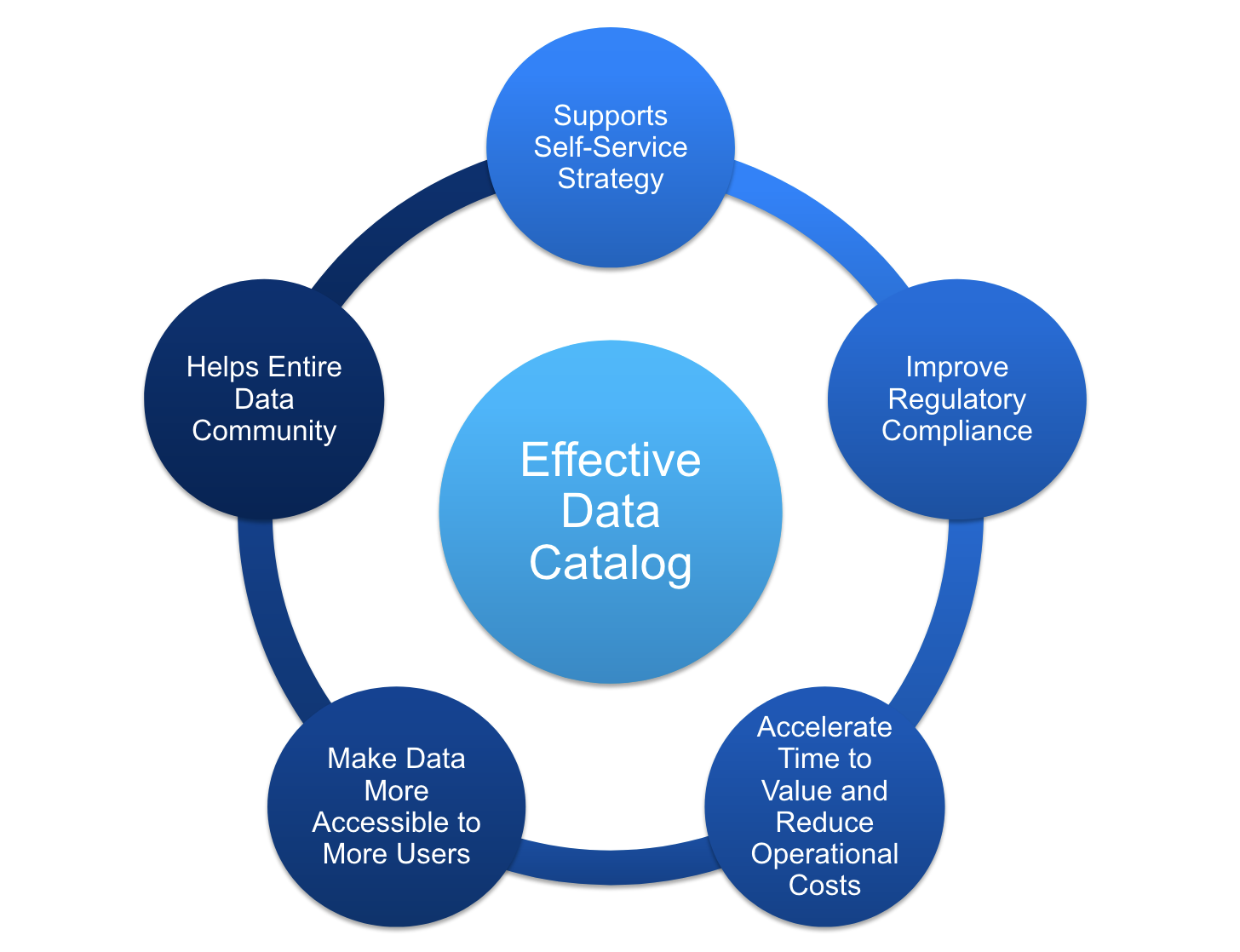
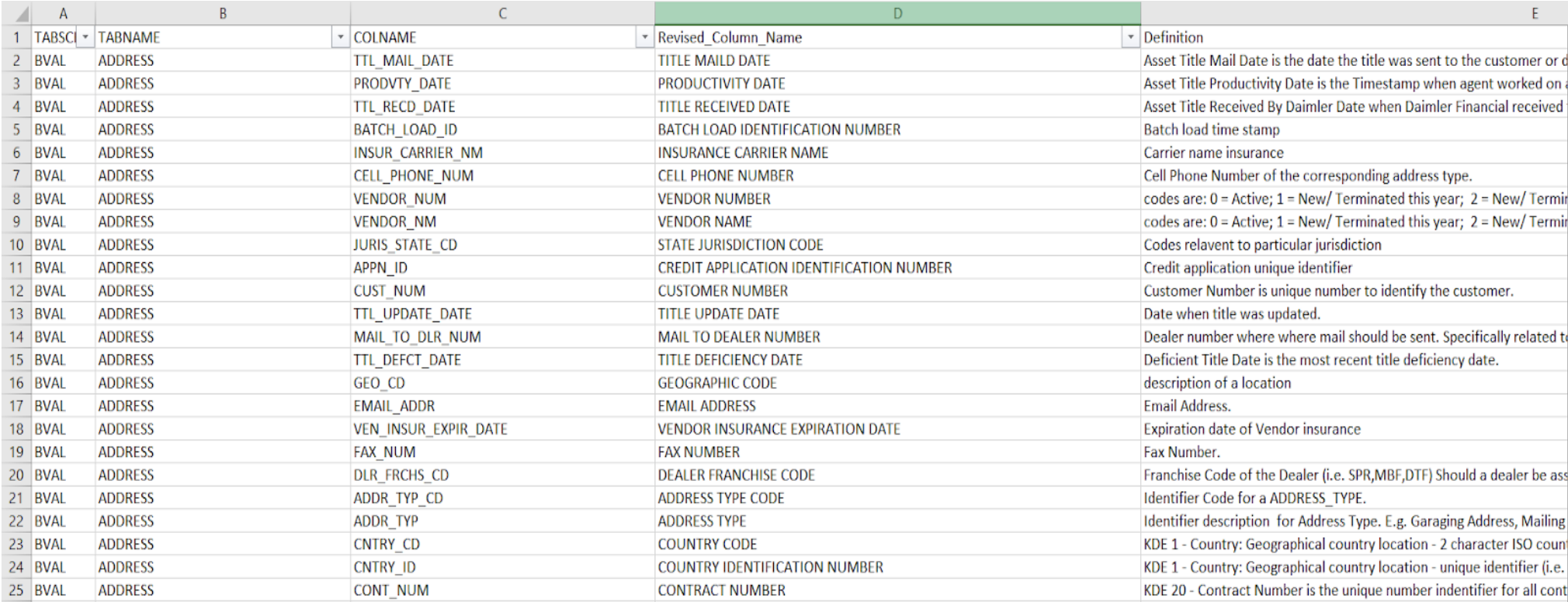
An effective, in house solution would be a data catalog application that a user can use to grab relevant information on specific subsets of data needed to identify trends and gain insight. We want it to be easy to use and efficient, querying through a huge volume of data quickly, but also accurate.